Service Discovery Pattern
MSA와 같은 분산 환경은 서비스간 원격 호출로 구성이 되고 IP와 Posrt를 이용하여 호출한다.
Cloud 환경에서의 인스턴스를 구축할 때 AutoScaling등으로 인한 IP, Port가 동적으로 변경될 일이 많다.
그래서 Client가 호출할 때 서비스 위치 (IP, Port)를 알아 낼 수 있는 기능이 필요한데, 이것을 Service Discovery라고 한다.
인스턴스가 새로 생성되면 해당 인스턴스에 정보를 Service registry에 등록해놓고, 이를 호출 하고자 하는 Client는 Service registry에 주소를 물어보고 그 주소를 이용해 서비스를 호출한다.
Service Discovery
Service Discovery의 구현 방법은 크게 Client side discovery와 Server side discovery 방식이 있다.
Client side discovery
Client가 Service registry에서 주소를 물어보고 위치(주소)를 찾아서 호출 하는 방식이다.
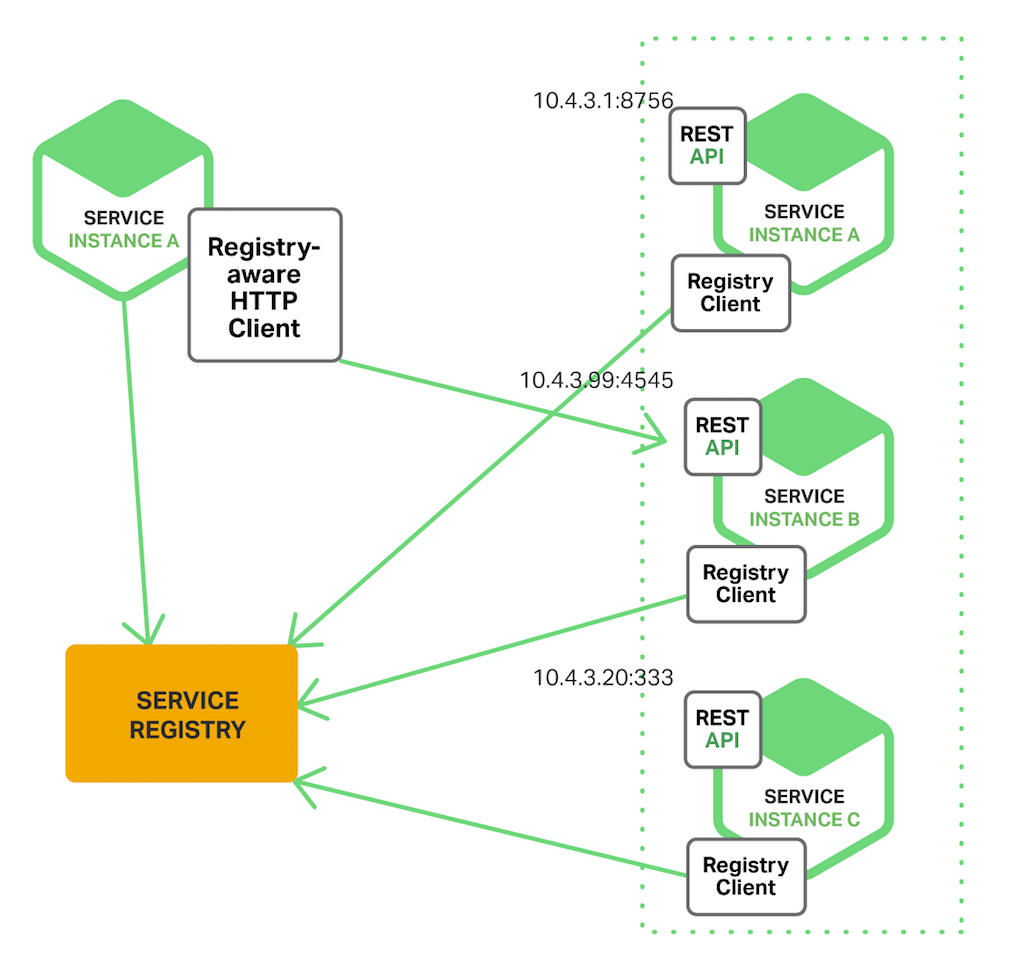
대표적으로 Netflix Eureka가 있다.
장점
- 간단하다.
- Client가 호출할 인스턴스의 정보를 알고 있기 떄문에 각 서비스별 Load balancing 방법을 선택 할 수 있음.
단점
- Client가 Service registry에 종속적이다.
- Client에서 discovery기능 구현해야한다. 사용하는 언어 및 프레임 워크에 대해 검색 로직을 구현해야함.
Server side discovery
호출되는 서비스 앞에 LB를 넣는 방식.
Client는 LB를 호출하고 LB가 Service Register로 부터 등록된 서비스(서버)의 정보를 전달하는 방식이다.
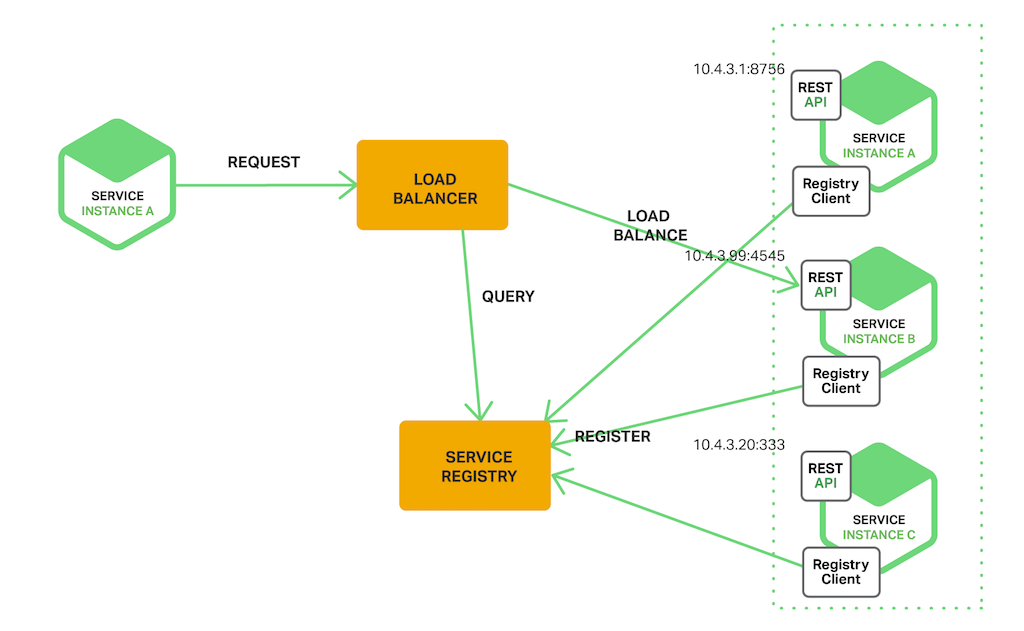
대표적으로 AWS ELB가 있다.
AWS ELB는 별도의 Service registry가 없고 EC2, ECS등이 ELB 자체에 등록된다고한다.
장점
- discovery의 세부 사항이 Client와 분리되어 있음
- Client는 단순히 LB에 요청을 하면된다. 언어 및 프레임 워크에 대한 검색 로직을 구현할 필요가 없음
단점
- LB가 배포 환경에서 제공해야함
- 제공하지 않는다면 관리해야하는 포인트가 늘어난다.
Service registry
Netflix Eureka
Netflix Eureka는 service registry의 좋은 예 이다.
- service 인스턴스를 등록 및 query를 위한 REST API를 제공
- POST 요청으로 등록, PUT 요청으로 refresh
- DELETE 요청으로 제거하거나 인스턴스 등록 시간이 초과되면 제거
- GET으로 service 인스턴스 검색 할 수 있다.
etcd
공유 구성 및 서비스 검색에 사용되는 고가용성에 분산된 일관성있는 key value 저장소.
설정을 공유하고 service discover를 위해 사용되기도 함.
HashiCorp consul
음 hashicorp 여러 제품은 보긴했는데 찾아보다가 발견함
service들을 discover하고 설정하기 위한 툴이라고 함.
API를 제공하고 health check을 통해 서비스 가용여부 판별
Apache zookeeper
분산 어플러키이션을 위해 널리 사용되는 coordination 서비스
참고